






Spatial AI
Simultaneous Localisation And Mapping (SLAM) has long been recognised as a core problem to be solved within countless emerging mobile applications that require intelligent interaction or navigation in an environment. Classical solutions to the problem primarily aim at localisation and reconstruction of a geometric 3D model of the scene. More recently, the community increasingly investigates the development of Spatial Artificial Intelligence (Spatial AI), an evolutionary paradigm pursuing a simultaneous recovery of object-level composition and semantic annotations of the recovered 3D model. It plays an important role in many emerging applications in which a smart mobile system is required to interact with the environment. Examples are given by intelligent transportation, robotics, or intelligence augmentation devices.
Object-level SLAM
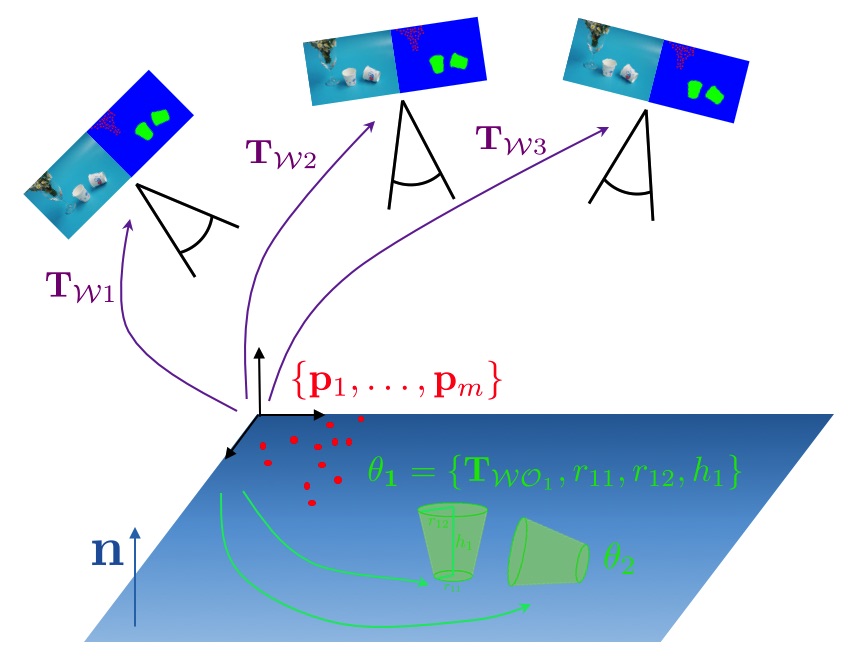
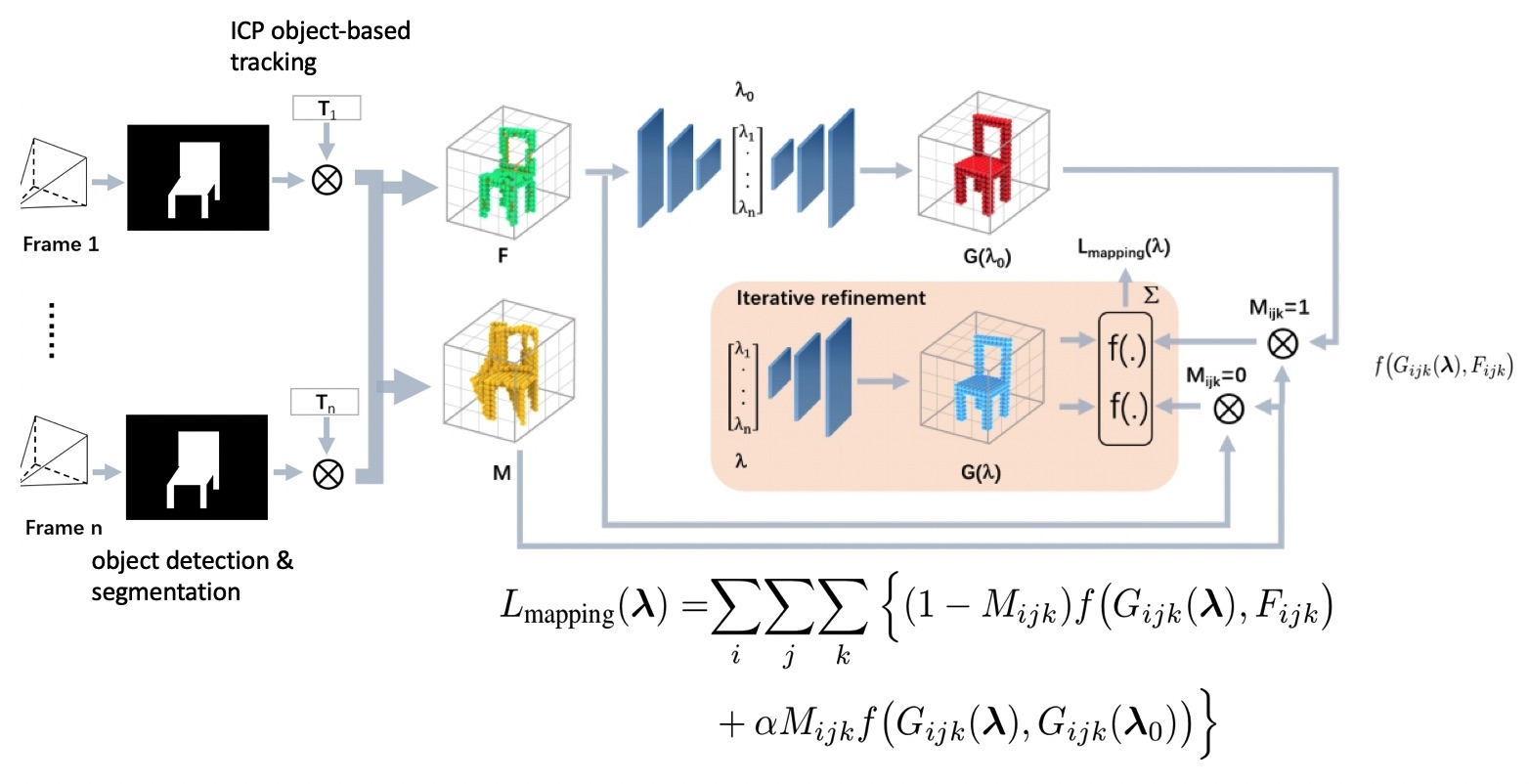
One example of an object-level SLAM framework is given by Deep-SLAM++. It employs object detectors to load and register full 3D models of objects. However, rather than just using fixed CAD models, we extend the idea to environments with unknown objects and only impose object priors by employing modern cathegory-level neural networks to generate complete model geometry proposals. The difficulty of using such predictions in a real SLAM scenario is that the prediction performance depends on the view-point and measurement quality, with even small changes of the input data sometimes leading to a large variability in the network output. As 3D shape representations have developed, MPL has proposed a number of object-level frameworks over the years to incorporate object-level priors into the estimation.
-
The first one consists of embedding the deep shape representation into a traditional measurement residual minimization framework. Available models in 2018 like MarrNet and Pix3D however demanded complicated estimation techniques such as CMA-ES.
L Hu, Y Cao, P Wu, and L Kneip. Dense object reconstruction from rgbd images with embedded deep shape representations. In Asian Conference on Computer Vision (ACCV), Workshop on RGB-D - sensing and understanding via combined colour and depth, Perth, Australia, December 2018 [pdf]
-
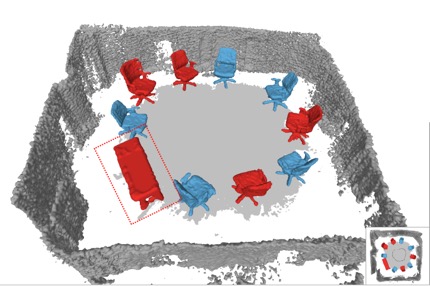
The second framework proposes a much simpler discrete selection strategy that finds the best among multiple proposals from different registered views by again checking residuals with respect to online depth measurements. The result–Deep-SLAM++–is an effective object-level RGBD SLAM system that produces compact, high-fidelity, and dense 3D maps with semantic annotations.
L Hu, W Xu, K Huang, and L Kneip. Deep-SLAM++: object-level RGBD SLAM based on class-specific deep shape priors. ArXiv e-prints, 2019 [pdf]

-
More recently, MPL proposes NF-SLAM that benefits from modern, generative, implicit shape representations like Deep-SDF. This collaboration with Motovis Intelligent Technologies therefore makes use of a modern differentiable shape model in its back-end - a compact version of Deep-SDF tailored to the class vehicles. As can be seen in the below video, the approach is capable of reconstructing observed road-side vehicles with high fidelity even though only a stereo camera-based sparse VO framework is employed.
L Cui, Y Ding, R Hartley, Z Xie, L Kneip, and Z Yu. NF-SLAM: Effective, Normalizing Flow-Supported Neural Field Representations for Object-Level Visual SLAM in Automotive Applications. In Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2024 [pdf] [video]

3D pose estimation of objects
Object-level SLAM frameworks that embed canonical 3D object shape representations into the backend must simultaneously estimate and in particular first initialize the 3D pose of those objects. This is a particularly challenging problem if only a single RGB camera is used. MPL has proposed a number of methods to tackle this problem:
-
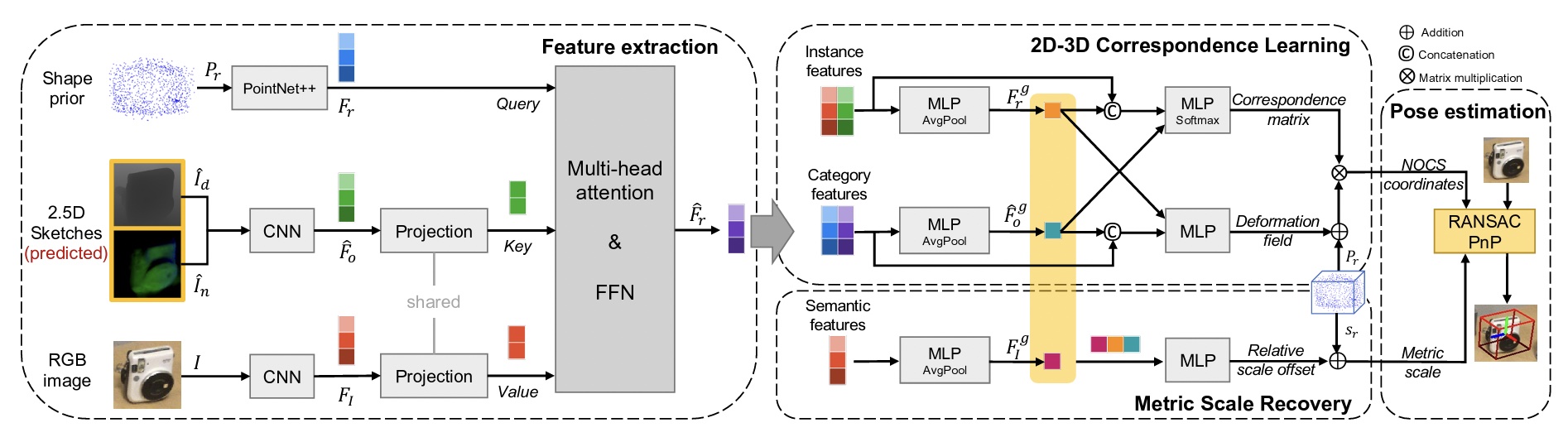
An intricate problem of single RGB frame-based 3D object pose estimation is scale fidelity. A straightforward approach would notably consist of simply predicting dense monocular depth and using this as a replacement for the depth channel in methods that for example rely on normalized object-coordinate representation. However, owing to the difficulty of correctly estimating depth (including metric scale), the input causes the final accuracy of the object pose estimation to degrade. MPL introduces a novel method that estimates the object pose from 2D-3D correspondences, where the 3D points are obtained from a predicted, normalized shape warp field and a decoupled scale estimation branch. The decoupling of the scale estimation notably leads to improved accuracy in terms of rotational pose estimation.
J Wei, X Song, W Liu, L Kneip, H Li, and P Ji. RGB-based Category-level Object Pose Estimation via Decoupled Metric Scale Recovery. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2024. [pdf] [code] [video]
-
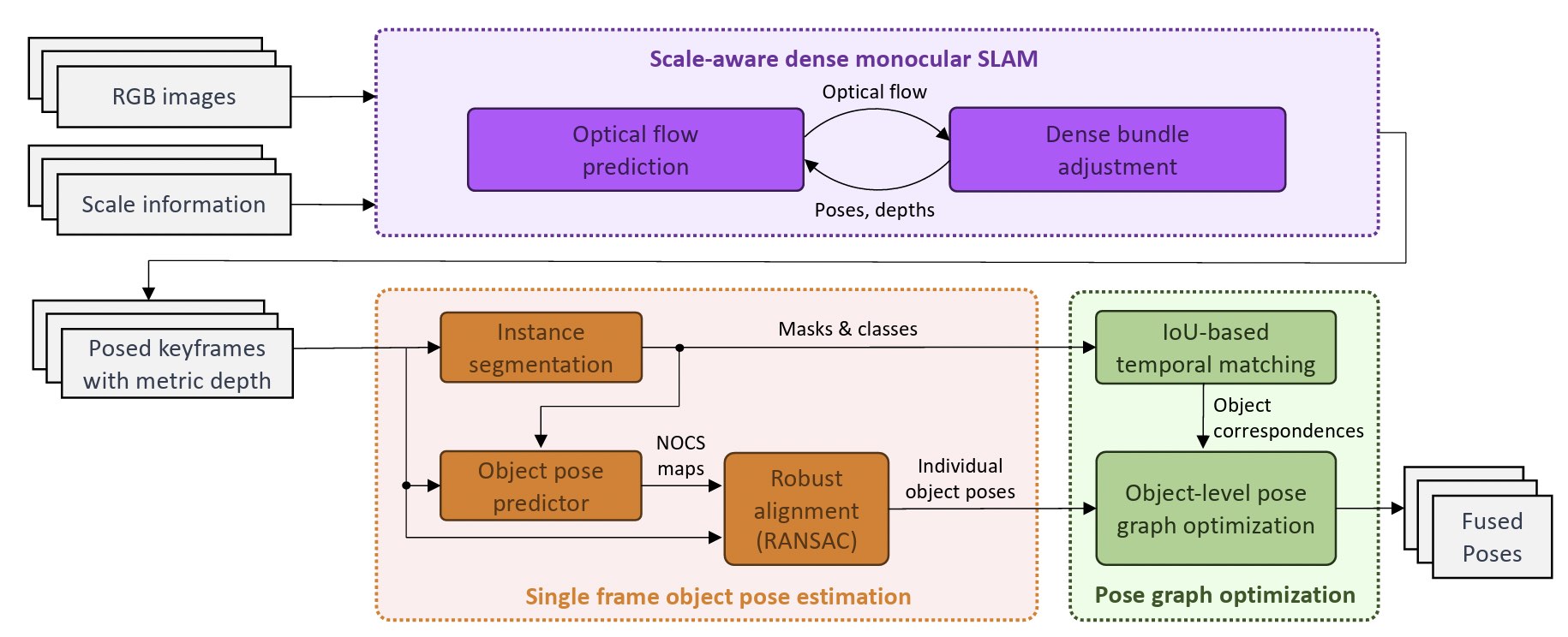
In another contribution, we ask the simple question: What if the object pose estimation does not have to be done from only a single frame, but what if the estimation is embedded into a continuous SLAM estimation framework (which naturally is the case in object-level SLAM). Two major changes can be made with respect to single-view pose estimation. First, we can rely on the depth estimates of the underlying SLAM framework in order to obtain an additional input to our object pose estimation module. If choosing a dense SLAM framework and additionally adding metric scale information (such as for example inertial-fusion), we can count on reasonably accurate per-frame metric dense depth estimations as an additional input. Second, the estimation can be an average of multiple frames rather than just a single frame prediction. The introduced framework is called MV-ROPE.
J Yang, Y Chen, X Meng, C Yan, M Li, R Cheng, L Liu, T Sun, and L Kneip. MV-ROPE: Multi-view Constraints for Robust Category-level Object Pose and Size Estimation. In Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2024. [pdf] [video]
-
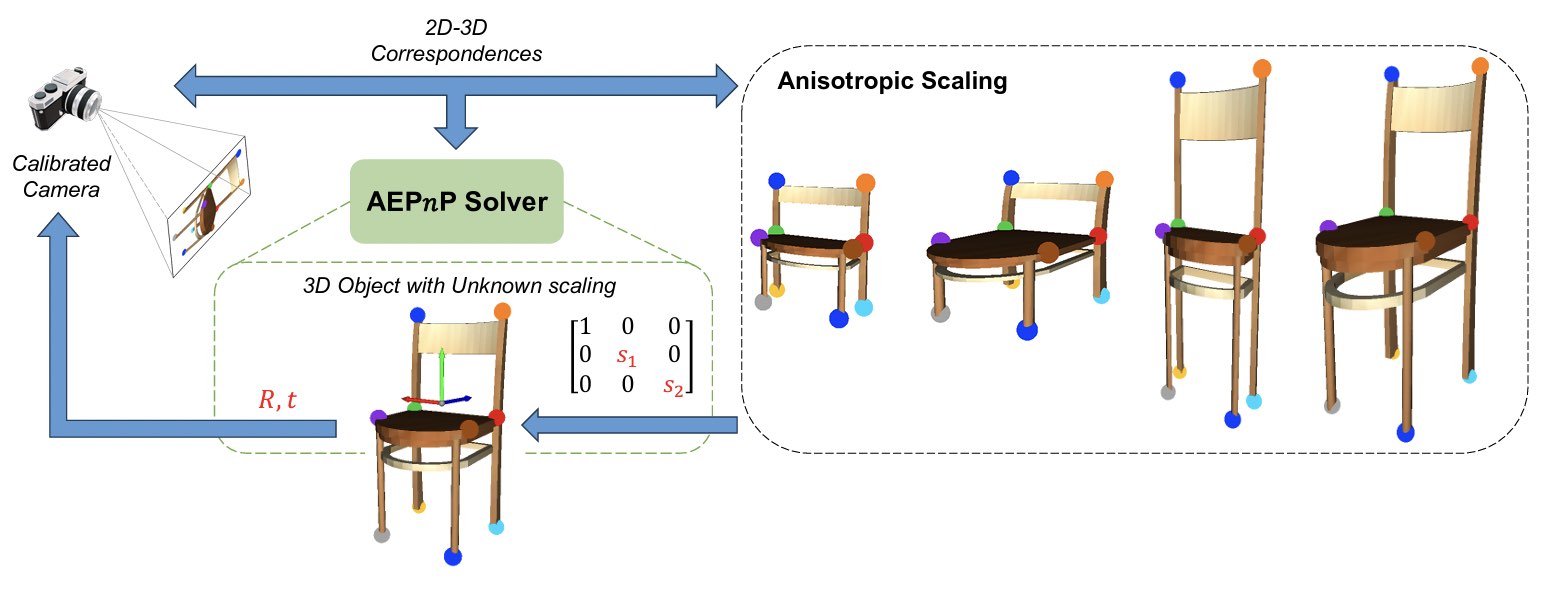
A special case is given when a reasonably accurate cathegory-level prior may be obtained, but it is only available up to an anisotropic scaling transformation. Examples of such cases may for example be given by tables or screens. In the below contribution, we propose a novel closed-form PnP solver that can-given 2D-3D correspondences, simply solve for the pose and the anisotropic scale.
J Wei, S Leutenegger, and L Kneip. AEPnP: A less-constrained EPnP solver for pose estimation with anisotropic scaling. In Proceedings of the European Conference on Computer Vision (ECCV), 2024a. Workshop on Scalable 3D Scene Generation and Geometric Scene Understanding [pdf] [code]
Neural representations for Predicting and Optimizing 3D Shapes
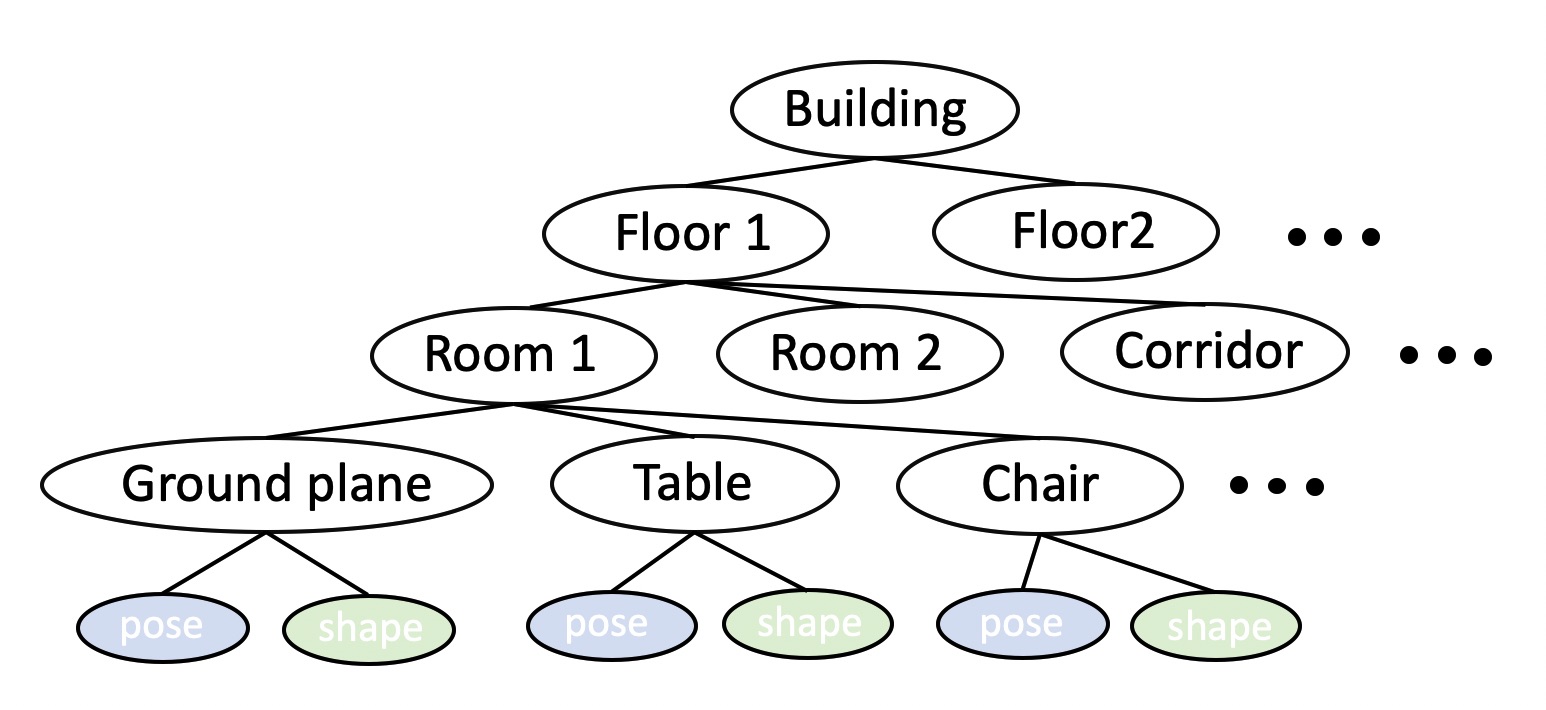
The key idea of object-level SLAM consists of operating with object-level priors in order to give high-level support to the estimation of the environment geometry. This can be achieved via a number of ways. For example, early object-level SLAM frameworks such as SLAM++ would simply reply on known prior 3D models for the specific objects encountered in the scene. At MPL, we have continuously worked on methods to relax the strong assumption of known object priors, and instead introduce cathegory-level representations to retrieve or optimize the 3D shape of objects.
-
A simple way consists of retrieving a CAD model from a large database of existing models. This can bypass the requirement for running more expensive neural representations.
J Wei, L Hu, C Wang, and L Kneip. Accurate Instance-Level CAD Model Retrieval in a Large-Scale Database. In Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2022. [pdf] [video 1] [video 2]

-
In another contribution, we propose Spotlights, a method that lets us directly predict complete point clouds from partial inputs. The interesting point about the representation consists of its sampling pattern: Point clouds are sampled along ray bundles which originate from a virtual sphere placed around the object. While not being an ultimately general representation and perhaps geared towards shapes that are more on the convex side, this representation is predicting structured point clouds and furthermore very compact as only 1D depths along rays need to be predicted.
J Wei, L Liu, R Cheng, W Jiang, M Xu, X Jiang, T Sun, S Schwertfeger, and L Kneip. Spotlights: Probing shapes from spherical viewpoints. In Proceedings of the Asian Conference on Computer Vision (ACCV), 2022. [pdf]

-
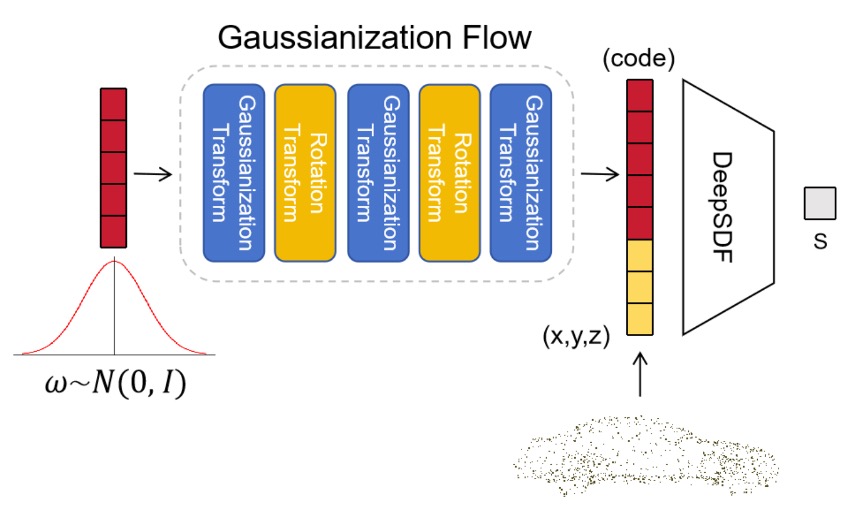
A more recent contribution of MPL in collabortion with Motovis Intelligent Technologies finally proposes a fully differentiable 3D shape representation that can be embedded into the back-end optimization of object-level SLAM frameworks (in particular, it is embedded into our NF-SLAM framework). The representation is a compact cathegory-level version of the highly successful implicit neural function resentation Deep-SDF, which takes a style vector and a 3D point sample as an input, and returns the corresponding spatial distance to the nearest surface. This representation can be readily embedded into back-end optimization, however suffers from convergence issues and artifacts in sparse or partial measurement scenarios. In order to circumvent this issue, NF-SLAM proposes to add a normalizing flow network to the latent code representation, which vastly improves performance in this scenario.
L Cui, Y Ding, R Hartley, Z Xie, L Kneip, and Z Yu. NF-SLAM: Effective, Normalizing Flow-Supported Neural Field Representations for Object-Level Visual SLAM in Automotive Applications. In Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2024. [pdf] [video]

Global localization
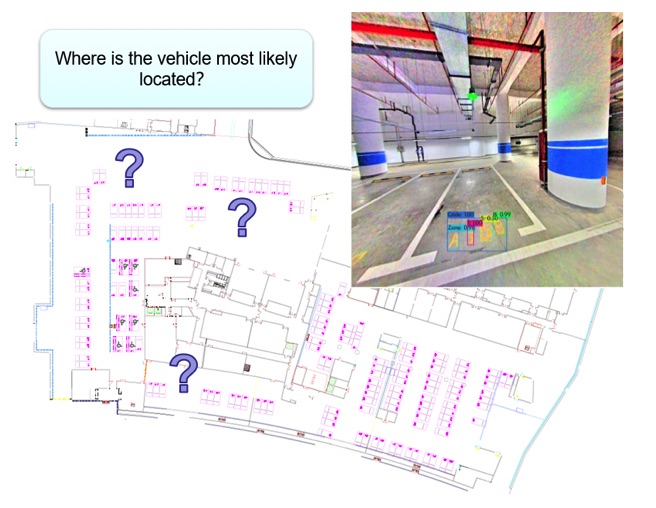
Autonomous Valet Parking (AVP) in an under-ground garage is an emerging smart vehicle solution that the community believes to be solvable with close-to-market sensors. Absence of GPS signals and a high degree of self similarity however render global visual localization in such environments a highly challenging problem. We present a novel underground parking localization method that relies on text recognition in the wild as well as optical character recognition (OCR) to automatically detect parking slot numbers. The detected numbers are then correlated with both geometric as well as semantic information extracted from an offline map of the environment. The resulting measurement model is embedded into a probabilistic Monte-Carlo localization framework. The success of our method is demonstrated on multiple real-world sequences in one of the largest underground parking garages in Shanghai.
L. Cui, C. Rong, J. Huang, A. Rosendo, and L. Kneip. Monte-Carlo Localization in Underground Parking Lots Using Parking Slot Numbers. In Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2021. [youtube] [bilibili]

Further industry translation
Our Spatial AI approaches have inspired the development of tailored localization solutions for applications in underground parking environments (AVP) at Motovis Intelligent Technologies Ltd. here in Shanghai, where MPL alumni are now working. The solutions perform localization on top of a high-definition map. They run in real-time on the embedded platform and make use of FPGA units for front-end feature detection. The maps are generated onboard. A mapping module takes the detected features and maps them into a high-definition 3D map of the environment containing semantic features such as parking spaces, pillars, and dashed lines. After mapping is concluded, the tracking module can then reuse these features in order to re-localize in the environment and enable solutions such as home-zone parking (HZP) and autonomous valet parking (AVP). The solutions are included into a prototype demo that show-cases fully autonomous path planning and driving execution in underground parkings here in Shanghai.

Other fundamental algorithms
The combination of geometric and semantic information maybe achieved at multiple levels including the more fundamental pose calculation algorithms embedded deep inside a SLAM system. We propose a novel solution to point set registration, and consider the specific case in which the point sets are segmented into semantically annotated parts. Such information may for example come from object detection or instance-level semantic segmentation in the registered RGB image. Prior methods incorporate the additional information to restrict or re-weight the point-pair associations occurring throughout the registration process. The present method introduces a novel hierarchical association framework for a simultaneous inference of semantic region association likelihoods. The formulation is elegantly solved using cascaded expectation-maximization, and demonstrates a substantial improvement over existing alternatives on open RGBD datasets. For more information including illustrations, please visit our page on pointset registration methods.
L. Hu, J. Wei, Z. Ouyang, and L. Kneip. Point Set Registration With Semantic Region Association Using Cascaded Expectation Maximization. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2021
Datasets

Several interesting Spatial AI approaches have already been presented, producing object-level maps with both geometric and semantic properties rather than just accurate and robust localisation performance. As such, they require much broader ground truth information for validation purposes. We therefore provide a new synthetic benchmark with accurate ground truth information about the scene composition as well as individual object shapes and poses. We furthermore propose evaluation metrics for all aspects of such joint geometric-semantic representations. It is our hope that the introduction of these datasets and proper evaluation metrics will be instrumental in the evaluation of current and future Spatial AI systems and as such contribute substantially to the overall research progress on this important topic.
Please head to the dataset webpage to gain access to the SSS Benchmark.
Yuchen Cao, Lan Hu, and Laurent Kneip. Representations and benchmarking of modern visual slam systems. MDPI Sensors, 20:2572, 2020 [pdf]