The SSS Vision Benchmark Suit
A project of MPL in ShanghaiTech University
A project of MPL in ShanghaiTech University


We take advantages of open source 3D computer graphics software toolset Blender to develop novel synthesized realistic computer vision benchmarks. Our interests focus on RGB-D, stereo, IMU, semantic object labelling, 3D object detection and reconstruction, hierachical structure of the map and furthermore, the compact map representation for upsoaring Spatail AI Systems. We aim to provide such semantic indoor datasets for visual SLAM and neural network researches. To achieve this goal, we utilize the most recent rendering engine of Eevee in Blender to efficiently generate customized & realistic indoor environments with semantically labelled furniture, and we set practically parameterized 35mm cameras to be close to the real cameras for data capture. Besides providing the raw data, our set of ground truth includes camera transformation information, IMU, semantic segmentation, 3D models of labelled objects and the benchmarks for each tasks. For each of our benchmarks, we also provide evaluation metrics of sensor poses, and class, pose, shape and completeness of objects. Our goal is to provide a handy framework of customizing accurate semantic dataset, and a benchmark of semantic Spatil AI evaluation and deep learning research for the community.

 All datasets and benchmarks on this page are copyright by MPL of ShanghaiTech University and published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. This means that you must attribute the work in the manner specified by the authors, you may not use this work for commercial purposes and if you alter, transform, or build upon this work, you may distribute the resulting work only under the same license.
All datasets and benchmarks on this page are copyright by MPL of ShanghaiTech University and published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. This means that you must attribute the work in the manner specified by the authors, you may not use this work for commercial purposes and if you alter, transform, or build upon this work, you may distribute the resulting work only under the same license.
When using this dataset in your research, we will be happy if you cite us!
@ARTICLE{Yuchen2020Sensors,
author = {Cao Yuchen and Hu Lan and Kneip Laurent},
title = {Representations and Benchmarking of Modern Visual SLAM Systems},
journal = {Sensors},
year = {2020}
}
Our work starts with the requirement of visual SLAM dataset along with accurate 3D semantic ground truth for another research, which combines SLAM and deep learning to recover complete 3D objects from partial input of moving camera. However, among numerous dataset online, few of them entirely meets our requirement, so we decide to make our own dataset.
Our first thought is to utilize OptiTrack tracking system and Faro Focus laser scanner to retrieve trajectories and 3D models. When we reconstruct objects models in the first scene, there are three main issues perplexed us:
• To reconstruct the complete point cloud of objects, Faro Focus has to scan the object from omni-direction under the same enviroment. Since the Faro Focus is expensive and cumbersome, the solution becomes to turn object (i.e. furniture) upside down, which becomes a tedious work if we want to get more dataset.
• Time stamp alignment is always an issue in dataset generation, the sensor at least includes laser sensor of tracking system, Kinect II and IMU data, those sensors work in different frame rate, which not only requires software development but also hardware support.
• Since tracking system is configured under the ceiling, and it was our only reliable device to get precise trajectory, which limits our choice of different scenatios.
Therefore, we start to look for a better way and got inspired by broad paper reading, we decide to synthesise realistic dataset. The newest render engine Eevee of Blender 2.81 is a handy tool for real time rendering, and helps us study how to generate accurate data from 3D computer graphics software. We mainly obtained texture materials and 3D models from CC0textures, Poliigon and TurboSquid. After building up our first synthesised indoor scenario, we face three new problems:
• How can we use Blender to generate realistic RGB images and Camera motions?
• How can we retrieve accurate semantic data, IMU data and trajectories from Blender?
• How can we make it a framework to automatically process above procedures by code?
Keeping that in mind, we explore around possible solutions in both computer graphics and computer vision area. Combining with the physical rules and virtual rendering environment, we find the right way to bake lumination and shadows inside Blender, tuning gamma correction parameter (CRF) and add noise to Bezier curves followed by camera to get realistic data. Another advantage of Blender is its compatibility with Python. We retrieve camera transformation matrix in world frame to get trajectories and easily mark semantic data via code with unique color as class label. The next direction we move towards is to amplify the sampling frequency 10 times to get accurate IMU data. Then we tidy up above processes into a framework to generate the next four scenes in a much efficiency.
However, the data is still different from the output of real cameras because of various noise from environment and mechanisms that we haven't taken into consideration for our data generation. The solution is to apply post process through C++ and Matlab codes to add depth collapse, motion blur and camera noise for RGB and depth data.
The above framework allows us to take fully control of the paramemters that we are interested in and gets us datasets that are as realistic as possible, we move to the next problem about how to evaluate the performance of different algorithms, we aim to provide a benchmark for semantic SLAM algorithm in tracking and 3D reconstruction.
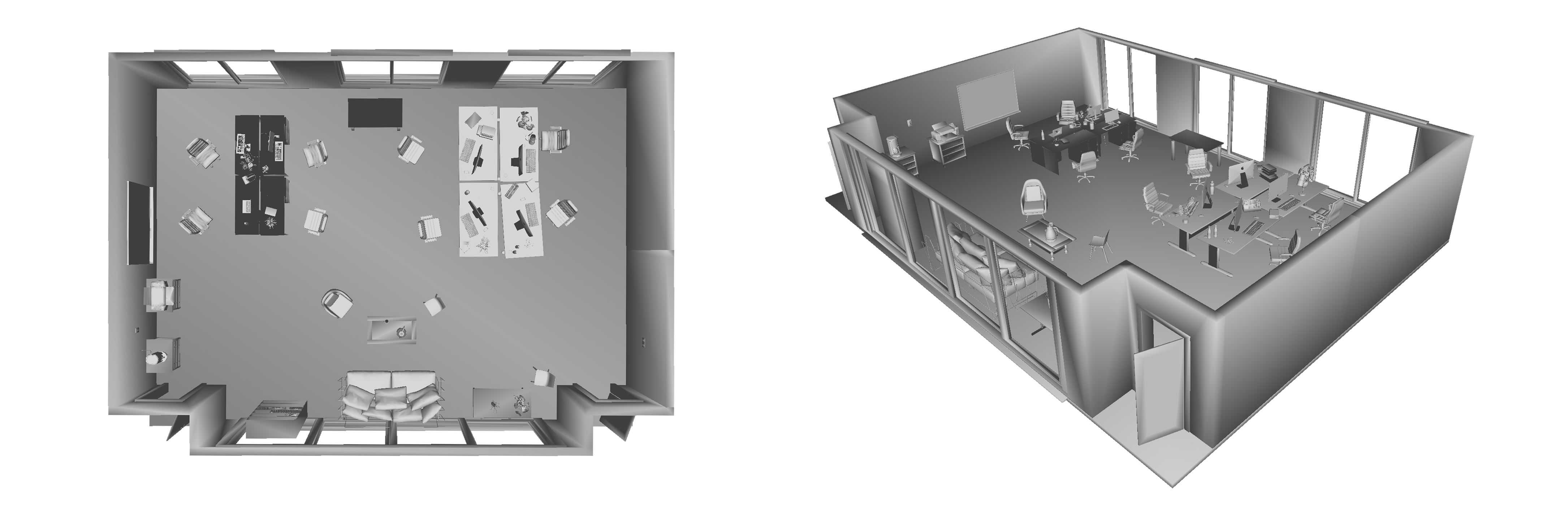
We currently provide 5 sets of indoor environment dataset, each of them contains RGB-D, stereo, RGB-IMU data, ground truth of semantic map, camera pose, 3D models and poses of semantic object. You are welcome to download them from links below this page. More dataset will come in the future. The details of the ground truth information can be found in Ground Truth tab. Besides, we provide codes and software guide for customizing dataset for your own purpose, they can be found in Code/Script tab. The example of data can be referred as below, which contains left camera, right camera, depth, segmentation map for the same frame.




| Duration[s] | Semantic Objects | Occlusion | Camera Shaking | Size[m] | |
|---|---|---|---|---|---|
| rm1 | 70 | (7): 2C1, 1C2, 1T1, 1T2, 1S1, 1TV1 | Slight | Slight | 6.4*6.5*3.1 |
| rm2 | 60 | (8): 1C1, 2C2, 2C3, 1C4, 1T1, 1T2 | Slight | Heavy | 8.0*6.0*3.2 |
| rm3 | 40 | (25): 8C1, 2C2, 1C3, 1T1, 1T2, 4T3, 2T4, 1T5, 4T6, 1S1 | Heavy | Slight | 10.0*14.0*2.8 |
| rm4 | 16.7 | (11): 3C1, 2C2, 2C3, 2T1, 1T2, 1T3 | No | None | 12.1*12.0*3.2 |
| rmC | 60 | (15): 2C1, 1C2, 2C3, 1C4, 2C5, 1C6, 1T1, 1T2, 1T3, 1T4, 1S1, 1TV1 | Slight | Slight | Combination of rm1 and rm2 |
In the column "Semantic Objects", C=Chair, T=Table, S=Sofa, TV=TV. e.g. 2C1=two chairs of type "1"
We provide both original rendered RGB-D and noise processed RGB-D for different research purpose. Each room has different setting of camera shaking, occlusion, light, and complexity of texture and shape, the trajectories of ground truth that we used below are examples, you can modify them and generate your own trajectory. The noise process method can be referred to our paper(link). In the below table, the left column is orginal rendered dataset; the right column is noise processed dataset.
rm1: A modern living room of 2100 frames. With rich semantic information of diversified furniture and decorations, it's made for evaluating the detection and modelling of objects as well as the overall quality of scene representations in terms of object shapes, poses, and overall scene composition.
| RGB Left[1.8GB] | RGB Right[1.8GB] | Depth[0.2GB] | Segmentation[0.2GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
| RGB Left Noise[2.7GB] | RGB Right Noise[2.7GB] | Depth Noise[2.2GB] | Segmentation[0.2GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
rm2: A vintage study room of 1800 frames. The environment contains simple chairs and tables, giving a low challenge in terms of scene modelling. The motion simulates hand-held camera motion, it's made for trajectory tracking and understanding the composition of the scene.
| RGB Left[1.6GB] | RGB Right[1.6GB] | Depth[0.4GB] | Segmentation[0.15GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
| RGB Left Noise[2.3GB] | RGB Right Noise[2.3GB] | Depth Noise[1.9GB] | Segmentation[0.15GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
rm3: A daily office room of 1200 frames. Office rooms are ordinary environments with complicated furniture and disordered office supplies that bring complexity for the surface of semantic objects. With hand-held sensor motion, the dataset is designed for evaluating the robustness, quality, and completeness of the recovered scene models in a real-world scenario where abundant occlusion exist.
| RGB Left[1GB] | RGB Right[1GB] | Depth[0.2GB] | Segmentation[0.15GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
| RGB Left Noise[1.5GB] | RGB Right Noise[1.5GB] | Depth Noise[1.3GB] | Segmentation[0.15GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
rm4: A spacious classroom of 500 frames, consists of simple tables and chairs aligned in a rough circle. With sufficient space between walls and foreground objects, no obvious occlusion exists in the data. Camera motion is smooth, the dataset gives a low challenge in terms of semantic detection, segmentation and tracking. Therefore, it can be used to perform preliminary testing for object-level SLAM systems.
| RGB Left[0.5GB] | RGB Right[0.5GB] | Depth[0.08GB] | Segmentation[0.03GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
| RGB Left Noise[0.6GB] | RGB Right Noise[0.6GB] | Depth Noise[0.5GB] | Segmentation[0.03GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
rmC: A combination of rm1 and rm2 with a corridor in between, of 1800 frames. The dataset is designed for research of relocalization and hierarchical scene representation problems, in which further higher-order priors such as orthogonality and parallelism are imposed, thus can be used to study the semantics and composition from the human intellectual perspective.
| RGB Left[1.7GB] | RGB Right[1.7GB] | Depth[0.4GB] | Segmentation[0.13GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
| RGB Left Noise[2.4GB] | RGB Right Noise[2.4GB] | Depth Noise[1.9GB] | Segmentation[0.13GB] |
| GroundTruth | IMU Data | Object Label & Map | Object Model |
All datasets and benchmarks on this page are copyright by MPL of ShanghaiTech University and published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. This means that you must attribute the work in the manner specified by the authors, you may not use this work for commercial purposes and if you alter, transform, or build upon this work, you may distribute the resulting work only under the same license.
When using this dataset in your research, we will be happy if you cite us!
@ARTICLE{Yuchen2020Sensors,
author = {Cao Yuchen and Hu Lan and Kneip Laurent},
title = {Representations and Benchmarking of Modern Visual SLAM Systems},
journal = {Sensors},
year = {2020}
}
We adjust virtual camera in Blender to be as real as commonly used camera, and intrinsic matrix of single camera and camera sets as simple as possible, you can customize the settings via the python code we provide. The uniform camera settings of 5 indoor scenarios are listed as below:
Camera Parameters:
| Parameters | |
|---|---|
| Focal Length | 24mm |
| Camera Sensor | 35mm |
| FOV | 72.2deg(horizontal) |
| Depth Distance Range | 0.1m - 20m |
| FPS | 30Hz |
| Focus Stop | F11 |
| Focus Distance | 10m |
| Distortion Coefficient | [k1 k2 k3 p1 p2]=[0.0 0.0 0.0 0.0 0.0] |
| Stereo Camera Baseline | 0.12m along x axis |
Camera Calibration:
| Parameters | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Intrinsic Matrix |
|
||||||||||||||||
| Left Projection Matrix |
|
||||||||||||||||
| Right Projection Matrix |
|
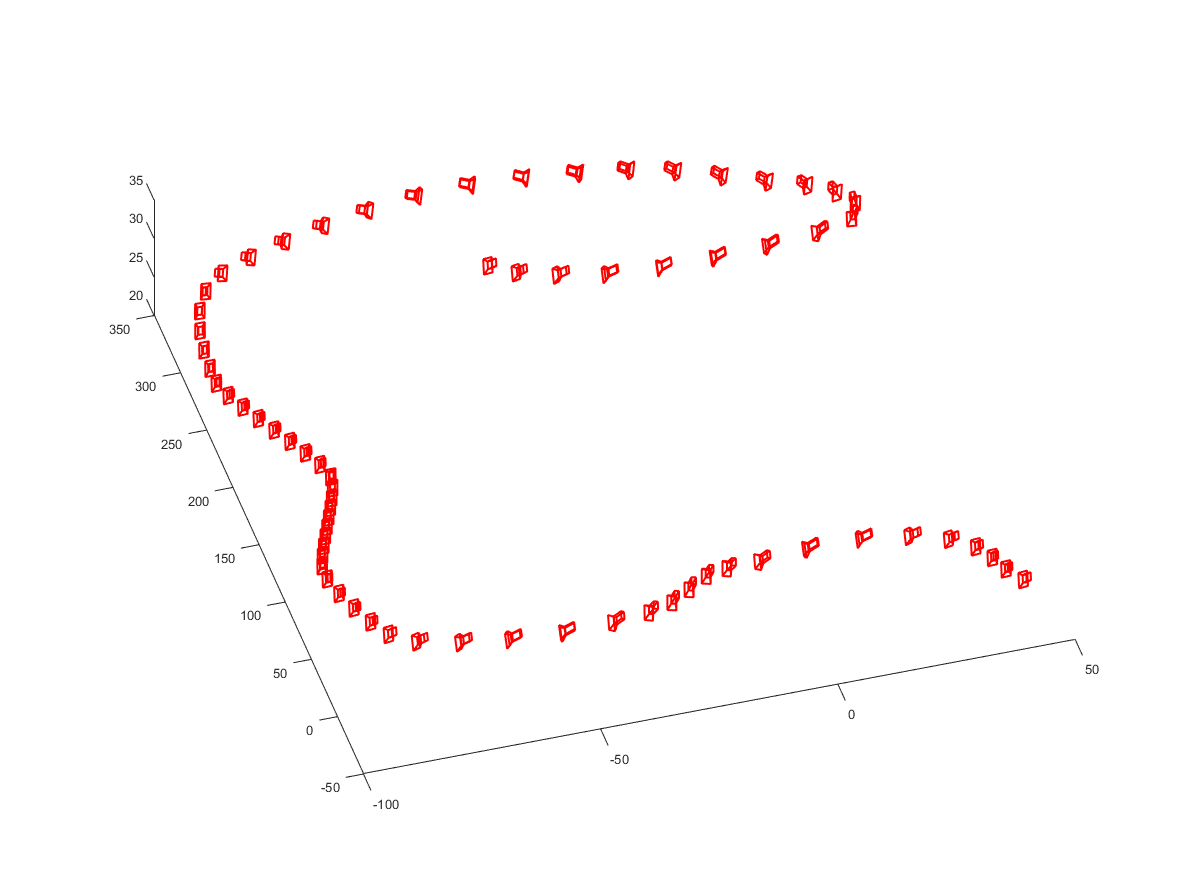
We provide the ground truth data of camera and object for each dataset, those parameters can also be customized by open source code for your own purpose, our definition and format for current 5 indoor scenarios are listed as below:
RGB-D & Segmentation Images:
-The color images are stored as 1024x768, 8-bit RGB images in PNG format.
-The depth images are stored as 1024x768, 16-bit monochrome images in PNG format.
-The segmentation images are stored as 1024x768, 16-bit RGB images in PNG format.
-The depth and segmentation images are pre-registered with left RGB, the correspondence is 1:1.
-The depth images are scaled by a factor of 20/65535=0.0003052 meter/bit.
• i.e., a pixel value of 1 in the depth image corresponds to a distance of 0.0003052 meter from the camera.
• A pixel value of 0 means missing value/no data.
Camera Pose Ground Truth:
-The pose ground truth records the transformation from camera to world.
-The format of ground truth from left to right is timestamp t, translation (xt yt zt), quaternion (wq xq yq zq), stored in .txt file.
-The world frame is defined as Z axis goes upward, the plane consist of X and Y axis goes horizontal.
-The unit of translation data is meter, the unit of time is 1/30s.
Object Data:
-The object ground truth records the transformation in the world frame.
-The object data is stored as .obj file along with .mtl file for texture information.
-The center/zero point in object frame is defined at the bottom center of each object.
• i.e. all the relative z is equal or larger than 0; And (x,y) of center point is in the geometry center, Y axis is the forward direction.
• However, objects are not strictly symmetrical, the center point may vary respectively and not strictly centering.
Object Map & Semantic Label:
-The data in ObjectMap is recorded as object class, translation (xt yt zt) quaternion (wq xq yq zq), each line represent for one transformation of object.
-The data in ObjectColor is recorded as object class, (R G B A), the range is from 0 to 65535.
IMU Data:
-Gravity = [0 0 -9.81]
-The unit for linear acceleration is m/(s^2) and the unit for angular velocity is rad/s.
All datasets and benchmarks on this page are copyright by MPL of ShanghaiTech University and published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. This means that you must attribute the work in the manner specified by the authors, you may not use this work for commercial purposes and if you alter, transform, or build upon this work, you may distribute the resulting work only under the same license.
When using this dataset in your research, we will be happy if you cite us!
@ARTICLE{Yuchen2020Sensors,
author = {Cao Yuchen and Hu Lan and Kneip Laurent},
title = {Representations and Benchmarking of Modern Visual SLAM Systems},
journal = {Sensors},
year = {2020}
}
TODO:
All datasets and benchmarks on this page are copyright by MPL of ShanghaiTech University and published under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. This means that you must attribute the work in the manner specified by the authors, you may not use this work for commercial purposes and if you alter, transform, or build upon this work, you may distribute the resulting work only under the same license.
When using this dataset in your research, we will be happy if you cite us!
@ARTICLE{Yuchen2020Sensors,
author = {Cao Yuchen and Hu Lan and Kneip Laurent},
title = {Representations and Benchmarking of Modern Visual SLAM Systems},
journal = {Sensors},
year = {2020}
}
caoych@shanghaitech.edu.cn for any broken links and suggestions.